Goals
This is part 4 of 6 in our tutorial on Arabic RAG. I’ll be using this blog as a guide, but to actually run this tutorial, its best that you run this notebook as described in part 1.
Before diving in, I want to you to think about how much money it costs to embed 2M articles. Make an estimate and see how accurate your guess is at the end of the blog. You can find out what other people thought in this poll I conducted (spoiler in the comments).
Info
In this blog you will learn:
- What the challenges are with embedding for RAG at scale
- How to solve this quickly using 🤗 TEI and Inference Endpoints
- How to embed your chunks in a cost-effective manner
Getting your embeddings isn’t talked about enough. It’s always surprisingly difficult as you scale and most tutorials
aren’t at any real scale. The right answer used to be
exporting to ONNX with O4 level
optimization and running it from there. While not difficult it took a little know-how and some preparation. This usually
led to people just running it out of the box and not putting some love and care into the process. Recently there have
been a lot of developments.
Why TEI
The problem with getting the embeddings efficiently is that there are techniques that exist but they are not widely applied. 🤗 TEI solves a number of these:
- Token Based Dynamic Batching
- Using latest optimizations (Flash Attention, Candle and cuBLASLt)
- Fast and safe loading with safetensors
- Parallel Tokenization workers
Applying most of these is doable but quite tedious. Big thanks to Olivier for creating this!
Set up TEI
There are 2 ways you can go about running TEI, locally or with 🤗 Inference Endpoints. Given not everyone will want to use Inference Endpoints as it is paid I have instructions on how to do this locally to be more inclusive!
Start TEI Locally
I have this running in a nvidia-docker container, but there are other ways to install too. Note that I ran the following docker startup cell in a different terminal for monitoring and separation.
Note
The way I have written the docker command will pull the latest image each time its run. TEI is at a very early stage at the time of writing. You may want to pin this to a specific version if you want more repeatability.
As described in part 3, I chose sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 based on the STS ar-ar performance on mteb/leaderboard, it’s the top performer and half the size of second place! TEI is fast, but this will also make our life easy for storage and retrieval.
I use the revision=refs/pr/8 because this has the pull request with safetensors which is optional but faster.
Check out the pull request if you want to use a different embedding model and it doesnt have safetensors you can
convert it here.
echo "Copy and paste this in another terminal. Make sure you have installed nvidia-docker and build as described here:
https://github.com/huggingface/text-embeddings-inference#docker-build"
volume=$pwd/tei
model=sentence-transformers/paraphrase-multilingual-minilm-l12-v2
revision=refs/pr/8
docker run \
--gpus all \
-p 8080:80 \
-v $volume:/data \
-v /home/ec2-user/.cache/huggingface/token:/root/.cache/huggingface/token \
--pull always \
ghcr.io/huggingface/text-embeddings-inference:latest \
--model-id $model \
--revision $revision \
--pooling mean \
--max-batch-tokens 65536
Test Endpoint
echo "This is just a sanity check so you don't get burned later."
response_code=$(curl -s -o /dev/null -w "%{http_code}" 127.0.0.1:8080/embed \
-X POST \
-d '{"inputs":"What is Deep Learning?"}' \
-H 'Content-Type: application/json')
if [ "$response_code" -eq 200 ]; then
echo "passed"
else
echo "failed"
fi
Warning
I’ll be running the rest of the notebook with Inference Endpoints. If you are using the local version, you will need to make some minor code updates to point to the right endpoint.
Start TEI with Inference Endpoints
Another option is to run TEI on Inference Endpoints. Its cheap and fast. It took me less than 5 minutes to get it up and running!
Check here for a comprehensive guide. For our tutorial make sure to set these options IN ORDER:
- Model Repository =
transformers/paraphrase-multilingual-minilm-l12-v2 - Name your endpoint
TEI-is-the-best - Choose a GPU, I chose
Nvidia A10Gwhich is $1.3/hr. - Advanced Configuration
- Task =
Sentence Embeddings - Revision (based on this pull request for safetensors =
a21e6630 - Container Type =
Text Embeddings Inference
- Task =
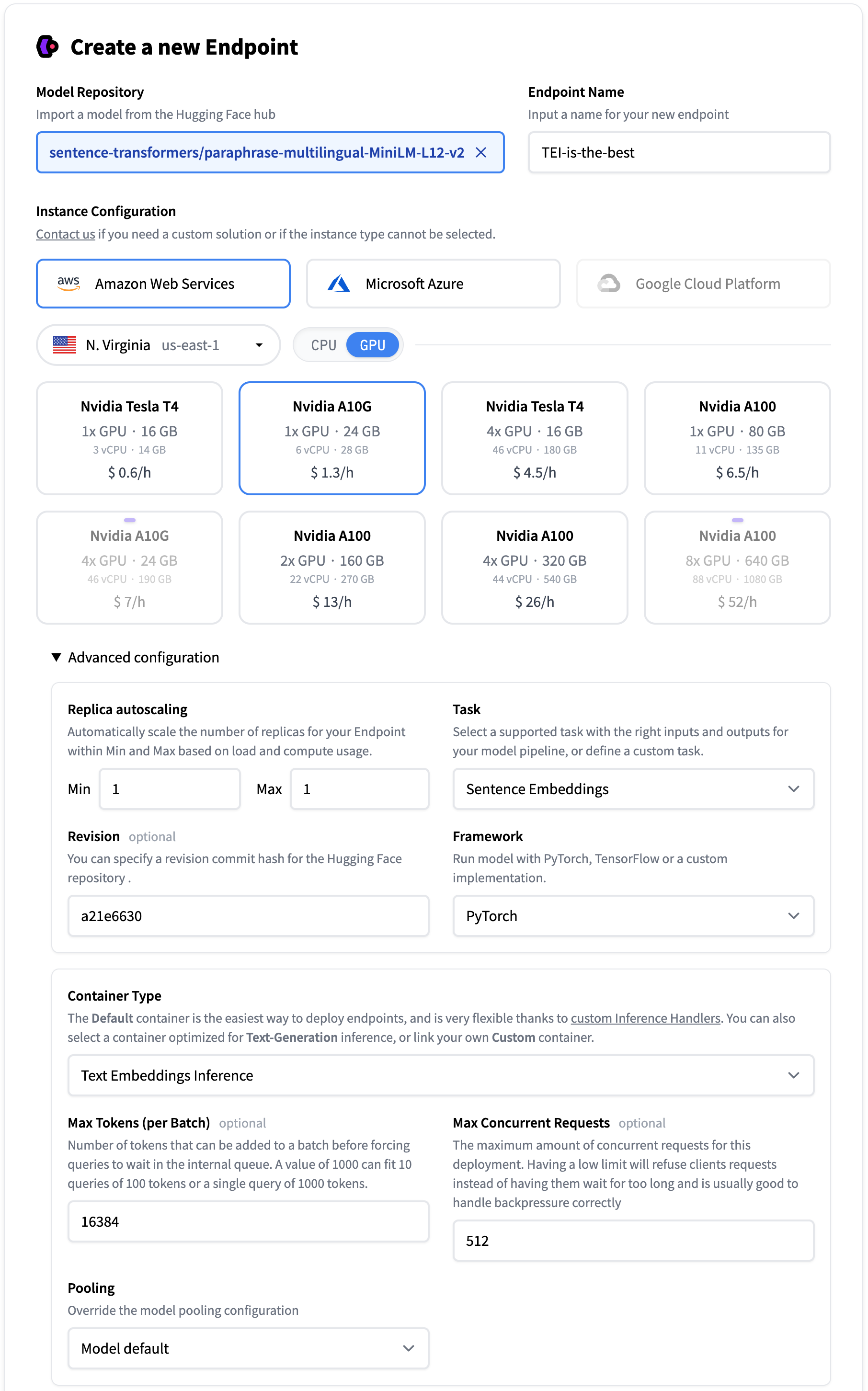
Set the other options as you prefer.
Test Endpoint
I chose to keep these hidden because its sensitive, getpass is a great way to hide sensitive data entry for public facing code.
import getpass
API_URL = getpass.getpass(prompt='What is your API_URL?')
bearer_token = getpass.getpass(prompt='What is your BEARER TOKEN? Check your endpoint.')
What is your API_URL? ········
What is your BEARER TOKEN? Check your endpoint. ········
Here we have a couple constants. The headers for our request and our MAX_WORKERS for parallel inference.
# Constants
HEADERS = {
"Authorization": f"Bearer {bearer_token}",
"Content-Type": "application/json"
}
MAX_WORKERS = 512
Let’s make sure everything is running correctly. Error messages with 512 workers is no fun.
import requests
def query(payload):
response = requests.post(API_URL, headers=HEADERS, json=payload)
return response.json()
output = query({
"inputs": "This sound track was beautiful! It paints the senery in your mind so well I would recomend it even to people who hate vid. game music!",
})
print(f'{output[0][:5]}...')
[0.0047912598, -0.03164673, -0.018051147, -0.057739258, -0.04498291]...
Ok great! We have TEI up and running!
Get Embeddings
Imports
import asyncio
from pathlib import Path
import json
import time
from aiohttp import ClientSession, ClientTimeout
from tqdm.notebook import tqdm
proj_dir = Path.cwd().parent
print(proj_dir)
/home/ec2-user/arabic-wiki
Config
As mentioned before I think it’s always a good idea to have a central place where you can parameterize/configure your notebook.
files_in = list((proj_dir / 'data/processed/').glob('*.ndjson'))
folder_out = proj_dir / 'data/embedded/'
folder_out_str = str(folder_out)
Strategy
TEI allows multiple concurrent requests, so its important that we dont waste the potential we have. I used the default
max-concurrent-requests value of 512, so I want to use that many MAX_WORKERS. This way we can maximize the
utilization of the GPU.
Im using an async way of making requests that uses aiohttp as well as a nice progress bar. What better way to do
Arabic NLP than to use tqdm which has an Arabic name?
Note that Im using 'truncate':True as even with our 225 word split earlier, there are always exceptions. For some
use-cases this wouldn’t be the right answer as throwing away information our retriever could use can lower performance
and cause insidious error propogation. You can pre-tokenize, assess token count, and re-chunk as needed.
This is our code to efficiently leverage TEI.
async def request(document, semaphore):
# Semaphore guard
async with semaphore:
payload = {
"inputs": document['content'],
"truncate": True
}
timeout = ClientTimeout(total=10) # Set a timeout for requests (10 seconds here)
async with ClientSession(timeout=timeout, headers=HEADERS) as session:
async with session.post(API_URL, json=payload) as resp:
if resp.status != 200:
raise RuntimeError(await resp.text())
result = await resp.json()
document['embedding'] = result[0] # Assuming the API's output can be directly assigned
return document
async def main(documents):
# Semaphore to limit concurrent requests. Adjust the number as needed.
semaphore = asyncio.BoundedSemaphore(512)
# Creating a list of tasks
tasks = [request(document, semaphore) for document in documents]
# Using tqdm to show progress. It's been integrated into the async loop.
for f in tqdm(asyncio.as_completed(tasks), total=len(documents)):
await f
Now that we have all the pieces in place we can get embeddings. Our high level approach:
- Read each processed
.ndjsonchunk file into memory - Use parallel workers to:
- Get embeddings for each
document - Update each
documentwith the corresponding embedding
- Get embeddings for each
- Verify that we got embeddings (always error check)
- Write these to file.
start = time.perf_counter()
for i, file_in in tqdm(enumerate(files_in)):
with open(file_in, 'r') as f:
documents = [json.loads(line) for line in f]
# Get embeddings
await main(documents)
# Make sure we got it all
count = 0
for document in documents:
if document['embedding'] and len(document['embedding']) == 384:
count += 1
print(f'Batch {i+1}: Embeddings = {count} documents = {len(documents)}')
# Write to file
with open(folder_out/file_in.name, 'w', encoding='utf-8') as f:
for document in documents:
json_str = json.dumps(document, ensure_ascii=False)
f.write(json_str + '\n')
# Print elapsed time
elapsed_time = time.perf_counter() - start
minutes, seconds = divmod(elapsed_time, 60)
print(f"{int(minutes)} min {seconds:.2f} sec")
0it [00:00, ?it/s]
0%| | 0/243068 [00:00<?, ?it/s]
Batch 1: Embeddings = 243068 documents = 243068
...
0%| | 0/70322 [00:00<?, ?it/s]
Batch 23: Embeddings = 70322 documents = 70322
104 min 32.33 sec
Wow, it only took ~1hr 45 min!
Lets make sure that we have all our documents:
!echo "$folder_out_str" && cat "$folder_out_str"/*.ndjson | wc -l
/home/ec2-user/arabic-wiki/data/embedded
2094596
Great, it looks like everything is correct.
Performance and Cost Analysis
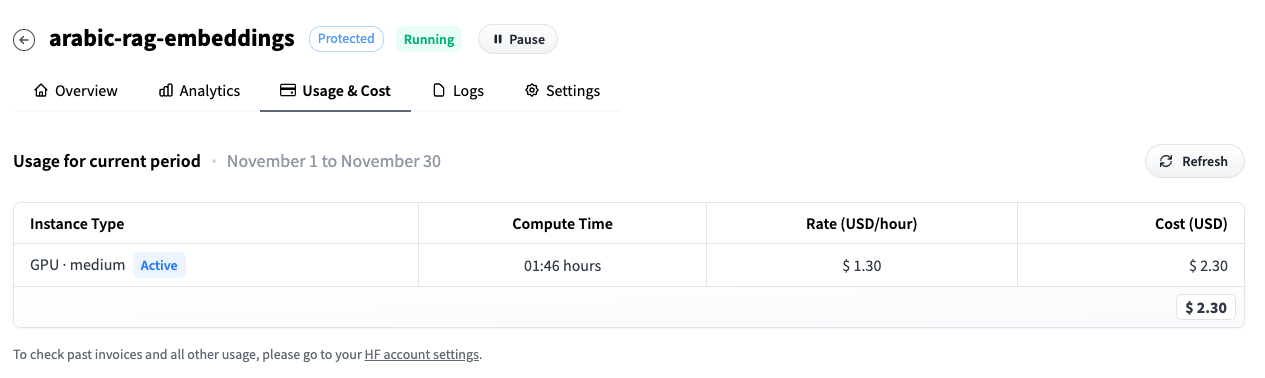
You can see that we are quite cost-effective! For only $2.30 we got text embeddings for ~2M articles!! How does that compare with your expectations?
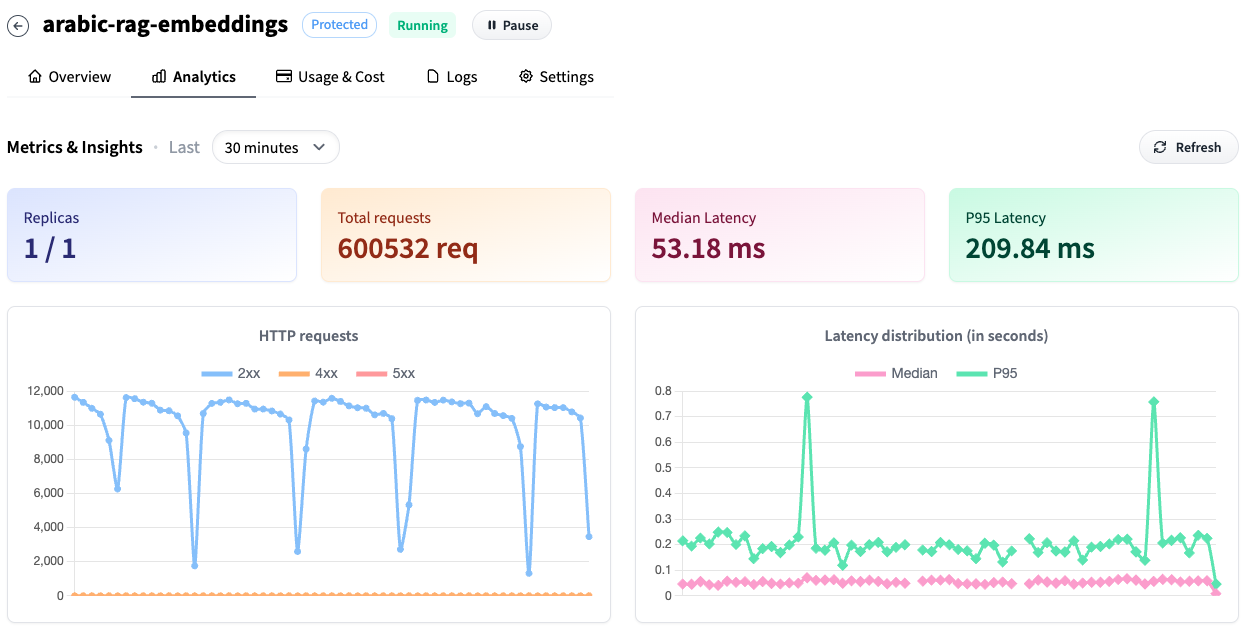
Note that the performance shown is over just the last 30 min window. Observations:
- We have a throughput of
~334/s - Our median latency per request is
~50ms
Next Steps
In the next blogpost I’ll show an exciting solution on VectorDB choice and usage. I was blown away since I expected it to take about a day to do the full ingestion, but it was MUCH FASTER 😱.