Tip
Please check this out in colab to run the code easily!
![]()
Introduction
Goal
I want jais-13B deployed with an API quickly and easily.
Info
In this blog you will learn:
- How to leverage TGI and Inference Endpoints with jais
- How to deploy a model on the HW of your choice using the Hub Client Library
- Fundamental concepts on how decoding works and why they matter
Approach
There are lots of options out there that are “1-click” which is really cool! I would like to do even better and make a “0-click”. This is great for those that are musophobic (scared of mice) or want scripts that can run without human intervention.
We will be using Text Generation Inference (TGI) as our serving toolkit as it is robust and configurable. For our hardware we will be using Inference Endpoints as it makes the deployment procedure really easy! We will be using the API to save us from using the dreaded mouse.
Pre-requisites
Deploying LLMs is a tough process. There are a number of challenges!
- These models are huge
- Slow to load
- Won’t fit on convenient HW
- Generative transformers require iterative decoding
- Many of the optimizations are not consolidated
TGI solves many of these, and while I don’t want to dedicate this blog to TGI there are a few concepts we need to cover to properly understand how to configure our deployment.
Prefilling Phase
In the prefill phase, the LLM processes the input tokens to compute the intermediate states (keys and values), which are used to generate the “first” new token. Each new token depends on all the previous tokens, but because the full extent of the input is known, at a high level this is a matrix-matrix operation that’s highly parallelized. It effectively saturates GPU utilization.
Prefilling is relatively fast.
Decoding Phase
In the decode phase, the LLM generates output tokens autoregressively one at a time, until a stopping criteria is met. Each sequential output token needs to know all the previous iterations’ output states (keys and values). This is like a matrix-vector operation that underutilizes the GPU compute ability compared to the prefill phase. The speed at which the data (weights, keys, values, activations) is transferred to the GPU from memory dominates the latency, not how fast the computation actually happens. In other words, this is a memory-bound operation.
Decoding is relatively slow.
Example
Lets take an example of sentiment analysis:
Pre-fill Phase
### Instruction: What is the sentiment of the input?
### Examples
I wish the screen was bigger - Negative
I hate the battery - Negative
I love the default appliations - Positive
### Input
I am happy with this purchase -
### Response
Above we have input tokens that the LLM will pre-fill. Note that we know what the next token is during the pre-filling phase. We can use this to our advantage.
Decoding Phase
POSITIVE
Above we have output tokens generated during decoding phase. Despite being few in this example we dont know what the next token will be until we have generated it.
Setup
Requirements
%pip
install - q
"huggingface-hub>=0.20"
ipywidgets
Imports
from huggingface_hub import login, whoami, create_inference_endpoint
from getpass import getpass
Config
ENDPOINT_NAME = "jais13b-demo"
login()
Some users might have payment registered in an organization. This allows you to connect to an organization (that you are a member of) with a payment method.
Leave it blank if you want to use your username.
who = whoami()
organization = getpass(prompt="What is your Hugging Face 🤗 username or organization? (with an added payment method)")
namespace = organization or who['name']
What is your Hugging Face 🤗 username or organization? (with an added payment method) ········
Inference Endpoints
Create Inference Endpoint
We are going to use the API to create an Inference Endpoint. This should provide a few main benefits:
- It’s convenient (No clicking)
- It’s repeatable (We have the code to run it easily)
- It’s cheaper (No time spent waiting for it to load, and automatically shut it down)
Here is a convenient table of instance details you can use when selecting a GPU. Once you have chosen a GPU in Inference
Endpoints, you can use the corresponding instanceType and instanceSize.
| hw_desc | instanceType | instanceSize | vRAM |
|---|---|---|---|
| 1x Nvidia Tesla T4 | g4dn.xlarge | small | 16GB |
| 4x Nvidia Tesla T4 | g4dn.12xlarge | large | 64GB |
| 1x Nvidia A10G | g5.2xlarge | medium | 24GB |
| 4x Nvidia A10G | g5.12xlarge | xxlarge | 96GB |
| 1x Nvidia A100 | p4de | xlarge | 80GB |
| 2x Nvidia A100 | p4de | 2xlarge | 160GB |
Note
To use a node (multiple GPUs) you will need to use a sharded version of jais. I’m not sure if there is currently a version like this on the hub.
Warning
This might take some experimentation to see what works for your budget and use-case. For short inferences, maybe an A10 would work well. For longer inferences maybe you need an A100.
hw_dict = dict(
accelerator="gpu",
vendor="aws",
region="us-east-1",
type="protected",
instance_type="p4de",
instance_size="xlarge",
)
This is one of the most important parts of this tutorial to understand well. Its important that we choose the deployment settings that best represent our needs and our hardware. I’ll just leave some high-level information here and we can go deeper in a future tutorial. It would be interesting to show the difference in how you would optimize your deployment between a chat application and RAG.
MAX_BATCH_PREFILL_TOKENS | docs |
Limits the number of tokens for the prefill operation. Since this operation take the most memory and is compute bound, it is interesting to limit the number of requests that can be sent
MAX_INPUT_LENGTH | docs |
This is the maximum allowed input length (expressed in number of tokens) for users. The larger this value, the longer prompt users can send which can impact the overall memory required to handle the load. Please note that some models have a finite range of sequence they can handle
I left this quite large as I want to give a lot of freedom to the user more than I want to trade performance. It’s important in RAG applications to give more freedom here. But for few-turn chat applications you can be more restrictive.
MAX_TOTAL_TOKENS | docs |
This is the most important value to set as it defines the “memory budget” of running clients requests. Clients will send input sequences and ask to generate
max_new_tokenson top. with a value of1512users can send either a prompt of1000and ask for512new tokens, or send a prompt of1and ask for1511max_new_tokens. The larger this value, the larger amount each request will be in your RAM and the less effective batching can be.
TRUST_REMOTE_CODE This is set to true as jais requires it.
QUANTIZE | docs |
Whether you want the model to be quantized
With jais, you really only have the bitsandbytes option. The tradeoff is that inference is a bit slower, but you can use much smaller GPUs (~3x smaller) without noticably losing performance. It’s one of the better reads IMO and I recommend checking out the paper.
tgi_env = {
"MAX_BATCH_PREFILL_TOKENS": "2048",
"MAX_INPUT_LENGTH": "2000",
'TRUST_REMOTE_CODE': 'true',
"QUANTIZE": 'bitsandbytes',
"MODEL_ID": "/repository"
}
A couple notes on my choices here:
- I used
derek-thomas/jais-13b-chat-hfbecause that repo has SafeTensors merged which will lead to faster loading of the TGI container - I’m using the latest TGI container as of the time of writing (1.3.4)
min_replica=0allows zero scaling which is really useful for your wallet though think through if this makes sense for your use-case as there will be loading timesmax_replicaallows you to handle high throughput. Make sure you read through the docs to understand how this scales
endpoint = create_inference_endpoint(
ENDPOINT_NAME,
repository="derek-thomas/jais-13b-chat-hf",
framework="pytorch",
task="text-generation",
**hw_dict,
min_replica=0,
max_replica=1,
namespace=namespace,
custom_image={
"health_route": "/health",
"env": tgi_env,
"url": "ghcr.io/huggingface/text-generation-inference:1.3.4",
},
)
Wait until its running
%%time
endpoint.wait()
CPU times: user 188 ms, sys: 101 ms, total: 289 ms
Wall time: 2min 56s
prompt = """
### Instruction: What is the sentiment of the input?
### Examples
I wish the screen was bigger - Negative
I hate the battery - Negative
I love the default appliations - Positive
### Input
I am happy with this purchase -
### Response
"""
endpoint.client.text_generation(prompt,
do_sample=True,
repetition_penalty=1.2,
top_p=0.9,
temperature=0.3)
'POSITIVE'
Pause Inference Endpoint
Now that we have finished, lets pause the endpoint so we don’t incur any extra charges.
endpoint = endpoint.pause()
print(f"Endpoint Status: {endpoint.status}")
Endpoint Status: paused
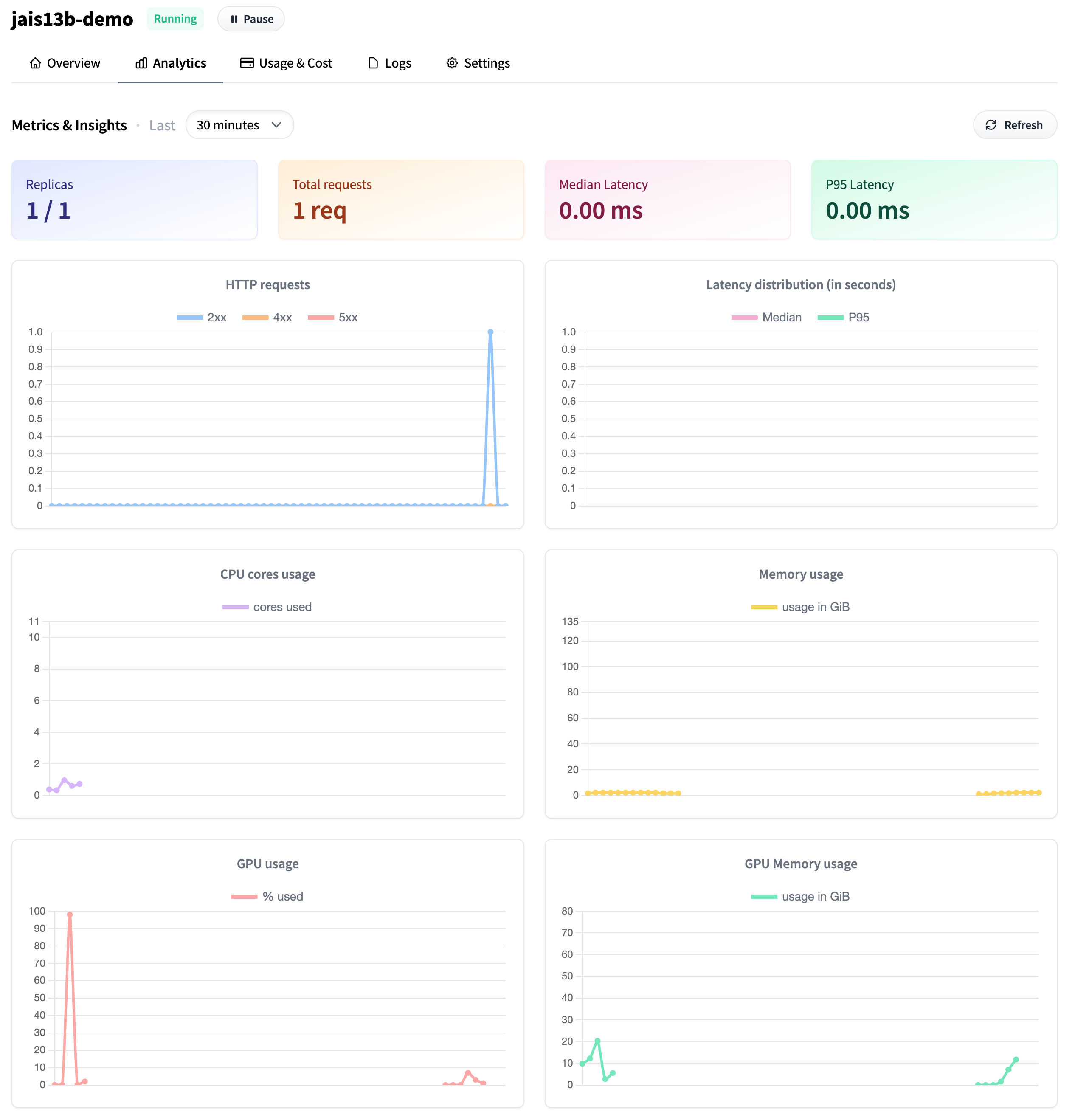
Analyze Usage
- Go to your
dashboard_urlprinted below - Check the dashboard
- Analyze the Usage & Cost tab
dashboard_url = f'https://ui.endpoints.huggingface.co/{namespace}/endpoints/{ENDPOINT_NAME}/analytics'
print(dashboard_url)
Analytics page
Dashboard page
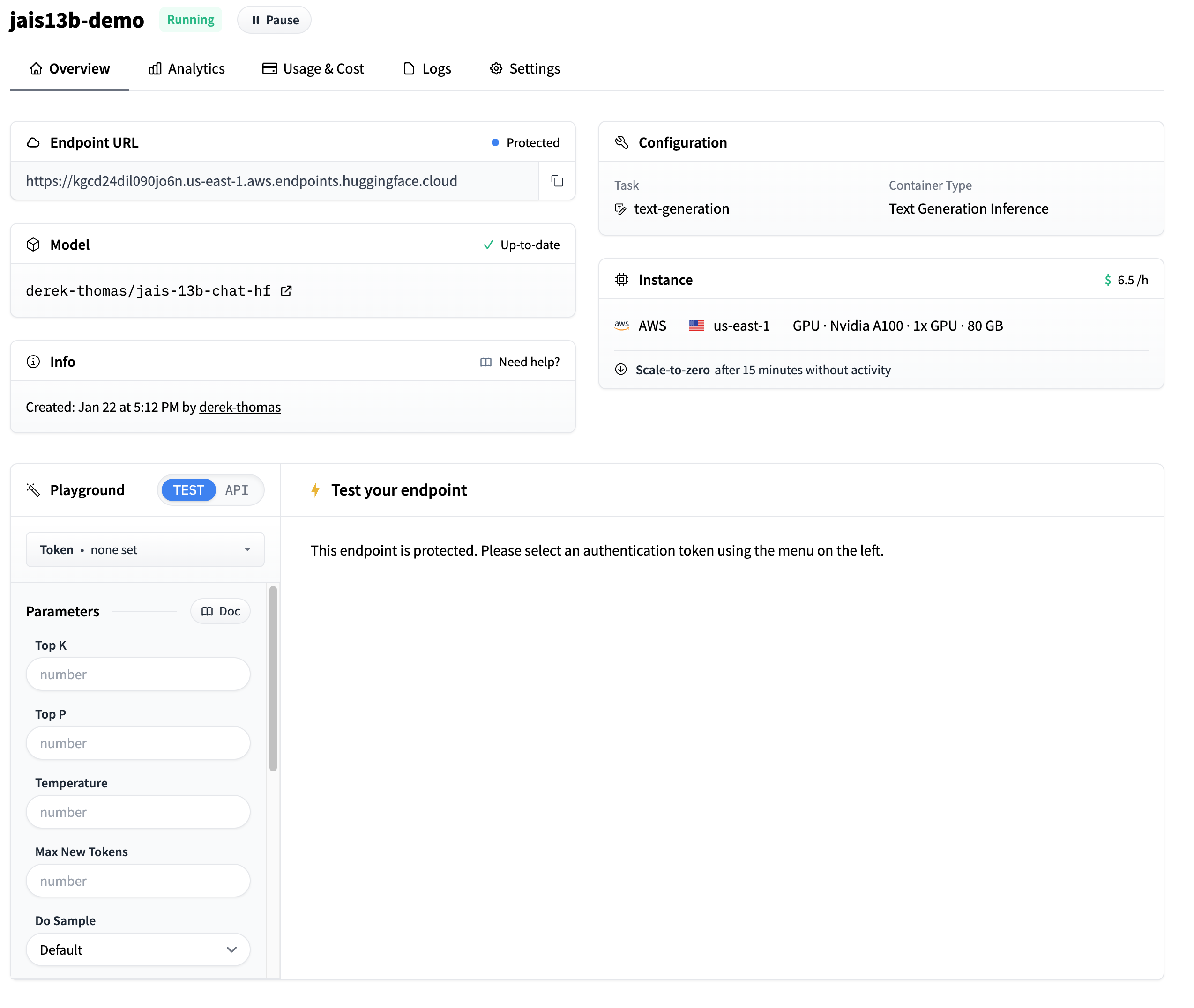
Delete Endpoint
endpoint = endpoint.delete()
if not endpoint:
print('Endpoint deleted successfully')
else:
print('Delete Endpoint in manually')
Endpoint deleted successfully